


Querying Multiple Data Sources with Trino

Problem
We want to build a reporting feature. But the data is in many different database engines: user information in mysql, post information in postgres,... we need a "distributed SQL query engine" support tool. Trino is a tool you can consider using
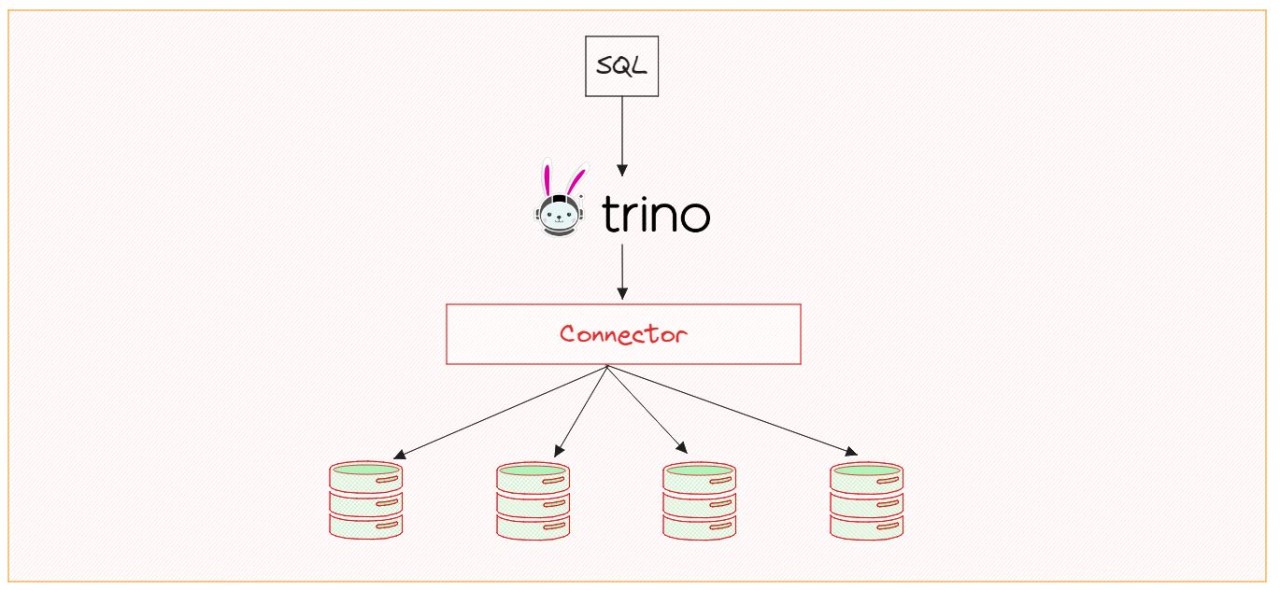
What is Trino
Trino is a distributed, scalable, open source SQL query engine with support for querying many data sources.
Why should you choose trino ?
- Trino is a highly parallel and distributed query engine, that is built from the ground up for efficient, low latency analytics.
- The largest organizations in the world use Trino to query exabyte scale data lakes and massive data warehouses alike.
- Trino is an ANSI SQL compliant query engine, that works with BI tools such as R, Tableau, Power BI, Superset and many others.
- Supports diverse use cases: ad-hoc analytics at interactive speeds, massive multi-hour batch queries, and high volume apps that perform sub-second queries.
- You can natively query data in Hadoop, S3, Cassandra, MySQL, and many others, without the need for complex, slow, and error-prone processes for copying the data.
- Access data from multiple systems within a single query. For example, join historic log data stored in an S3 object storage with customer data stored in a MySQL relational database.
- Trino is optimized for both on-premise and cloud environments such as Amazon, Azure, Google Cloud, and others.
- Trino is used for critical business operations, including financial results for public markets, by some of the largest organizations in the world.
- The Trino project is community driven project under the non-profit Trino Software Foundation.
Disadvantage
The biggest disadvantage when deploying trino is that it requires large RAM. So it will be expensive to maintain
How to trino work
Trino is a distributed system that utilizes an architecture similar to massively parallel processing (MPP) databases. Like many other big data engines there is a form of a coordinator node that then manages multiple worker nodes to process all the work that needs to be done.
An analyst or general user would run their SQL which gets pushed to the coordinator. In turn the coordinator then parses, plans, and schedules a distributed query. It supports standard ANSI SQL as well as allows users to run more complex transformations like JSON and MAP transformations and parsing.
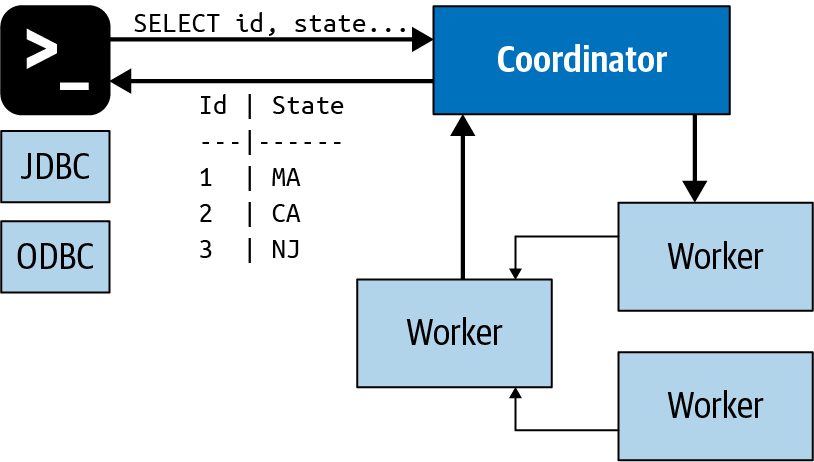
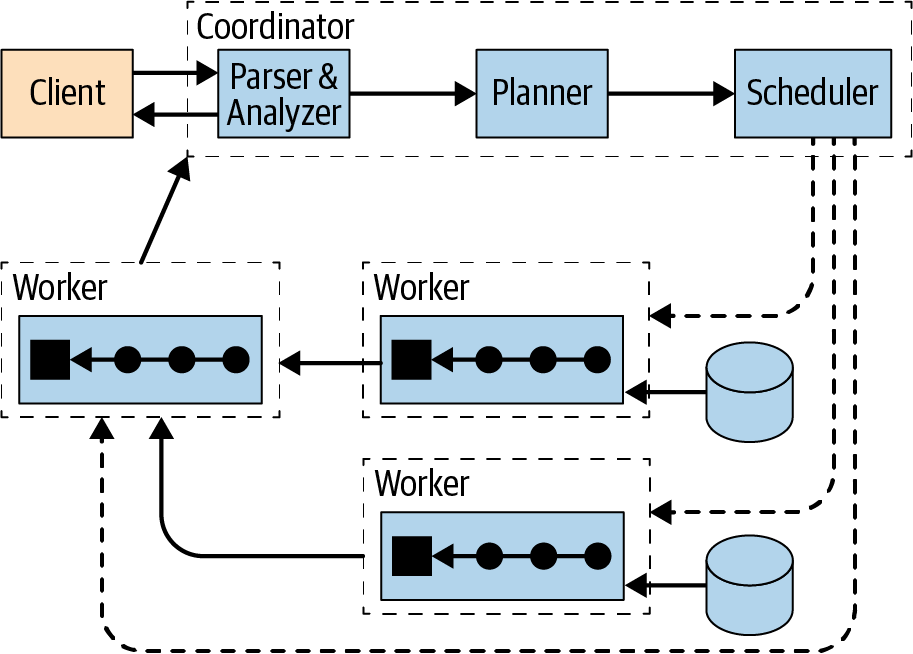
Practice
back to the initial problem of writing. Do we need to create a report feature with user information in the postgres database and post information in mysql.
-
set up trino + database via docker
- create docker-compose file
# docker-compose.yml version: '3.0' services: trino: ports: - "8080:8080" image: "trinodb/trino" volumes: - ./trino:/etc/trino userdb: image: postgres environment: POSTGRES_PASSWORD: 123 contentdb: image: mysql environment: MYSQL_ROOT_PASSWORD: 123 - run this docker-console file. And then we can access trino dashboard via http://localhost:8080.
Here we can track incoming, executing, completed and error queries
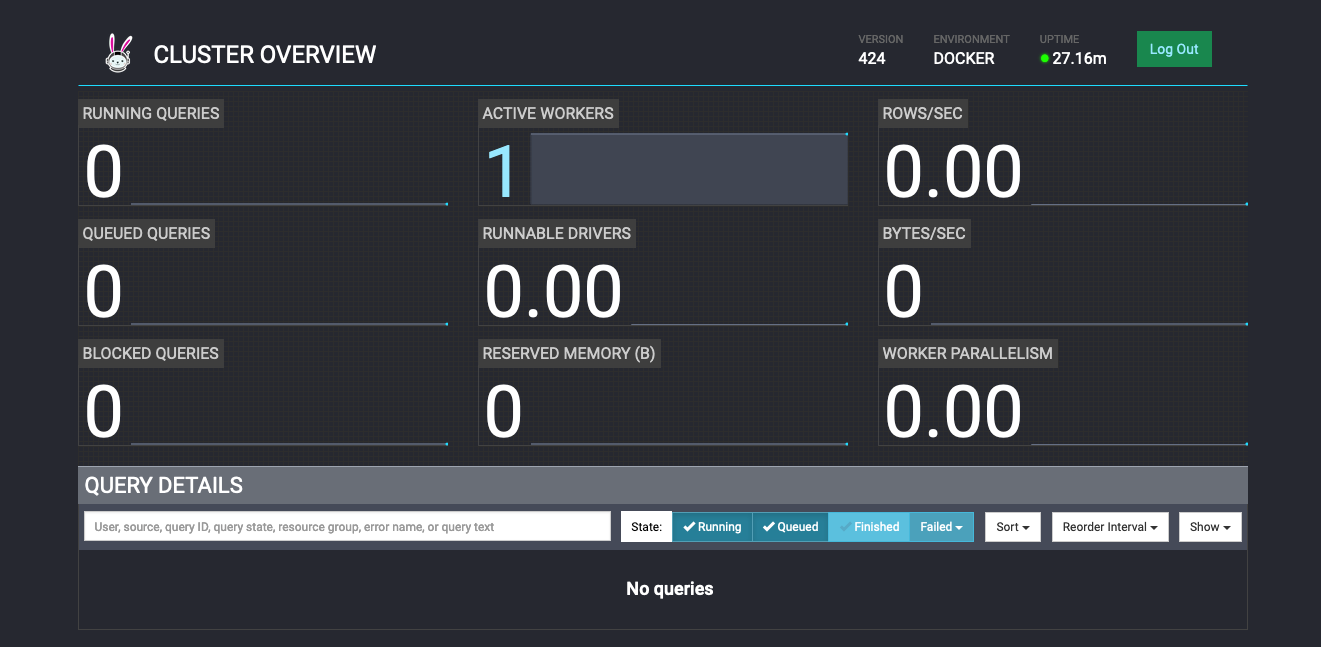
- create docker-compose file
-
create sample user data (Postgres)
# user.sql CREATE TABLE public."user" ( id int NOT NULL GENERATED BY DEFAULT AS IDENTITY, display_name text NOT NULL, birthday text NULL ); INSERT INTO public."user" (id, display_name, birthday) VALUES(1, 'user1', '01/12/1990'); INSERT INTO public."user" (id, display_name, birthday) VALUES(2, 'user2', '01/12/1990'); INSERT INTO public."user" (id, display_name, birthday) VALUES(3, 'user3', '01/12/1990'); INSERT INTO public."user" (id, display_name, birthday) VALUES(4, 'user4', '01/12/1990');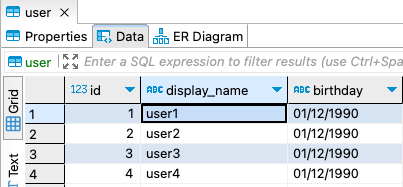
-
create sample blog data (MySQL)
CREATE TABLE contentdb.blog ( id int auto_increment NULL, name varchar(100) NULL, description varchar(100) NULL, user_id int NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci; INSERT INTO contentdb.blog (id, name, description, user_id) VALUES(1, 'blog 1', 'descript 1', 1); INSERT INTO contentdb.blog (id, name, description, user_id) VALUES(2, 'blog 2', 'descript 2', 1); INSERT INTO contentdb.blog (id, name, description, user_id) VALUES(3, 'blog 3', 'descript 3', 1); INSERT INTO contentdb.blog (id, name, description, user_id) VALUES(4, 'blog 4', 'descript 4', 2); INSERT INTO contentdb.blog (id, name, description, user_id) VALUES(5, 'blog 5', 'descript 5', 2); INSERT INTO contentdb.blog (id, name, description, user_id) VALUES(6, 'blog 6', 'descript 6', 3); INSERT INTO contentdb.blog (id, name, description, user_id) VALUES(7, 'blog 7', 'descript 7', 3); INSERT INTO contentdb.blog (id, name, description, user_id) VALUES(8, 'blog 8', 'descript 8', 3);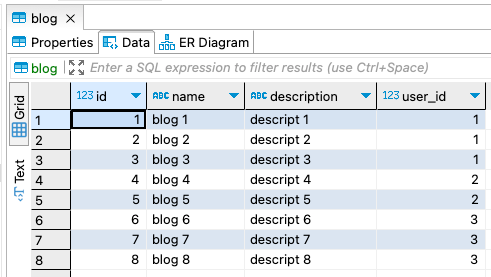
-
prepare catalog config for trino This is the connection information to the databases
- catalog/userdb.properties
connector/userdb.name=postgresql connection-url=jdbc:postgresql://userdb:5432/postgres connection-user=postgres connection-password=123 - catalog/contentdb.properties
connector.name=postgresql connection-url=jdbc:postgresql://userdb:5432/postgres connection-user=postgres connection-password=123
- catalog/userdb.properties
-
run SQL tests
trino http://localhost:8080 \ --catalog userdb \ --source postgres \ --schema public \ --execute 'select * from user u inner join contentdb.contentdb.blog b on b.user_id=u.id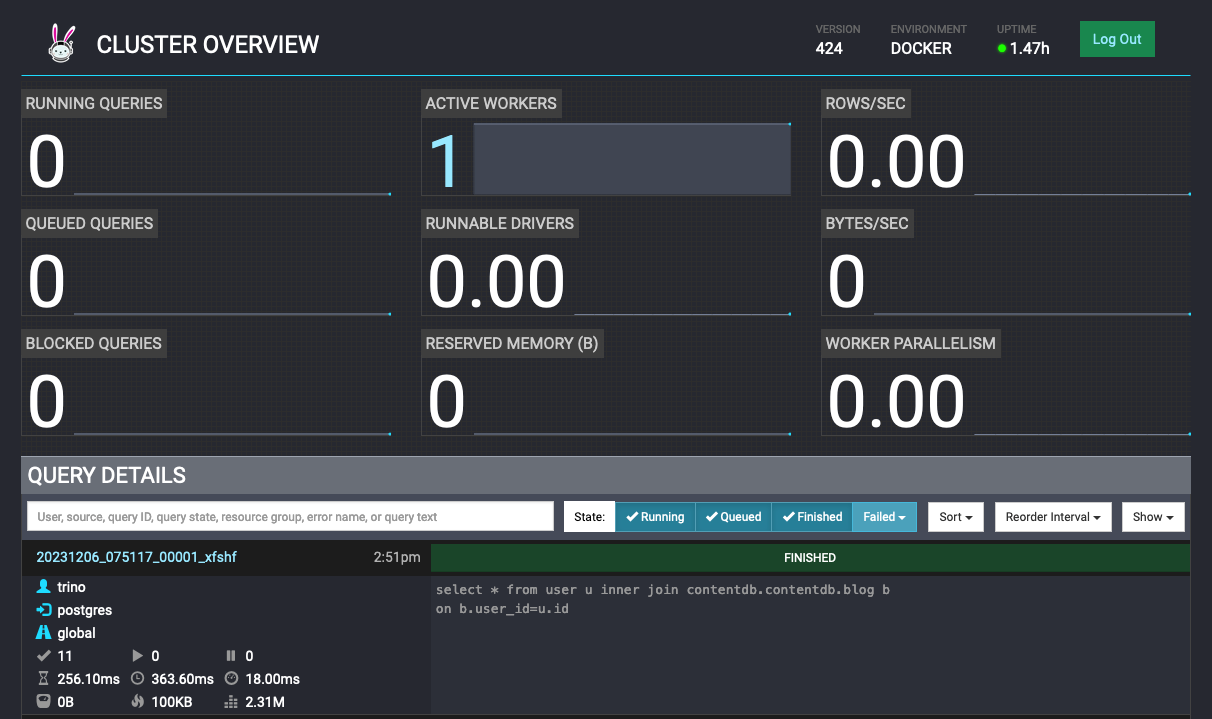
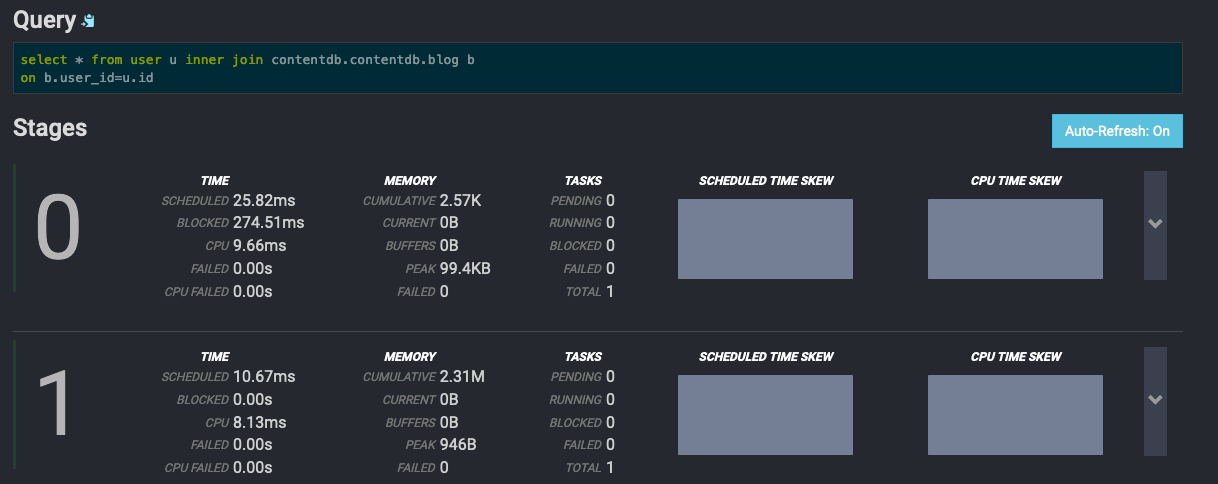
Note that the data to be collected can be large and time-consuming. So you can configure the callback URL for trino. It will call this URL every time a JOB is completed
Advanced Features
There are still many features on Trino. You can explore here trino
Thank for reading the post