

When using Postgres SASS we are not care about how cloud provider managed them but one a day, we need to run a postgres cluster on premise, we need to care about that. We setup 2,3 postgres server, once act as primary server, the other one act as standby server. When primary server is down, we login into standby server then triggering reload them, move them to primary instance. But there is a tool help us do it automaticaly.

repmgr is an open-source tool suite for managing replication and failover in a cluster of PostgreSQL servers. It enhances PostgreSQL's built-in hot-standby capabilities with tools to set up standby servers, monitor replication, and perform administrative tasks such as failover or manual switchover operations.
In this scope of this post, i will deployed two postgres server using docker compose. Then put haproxy in the front-of them, haproxy will detect the primary and proxy traffic to this server. The architecture look like this.
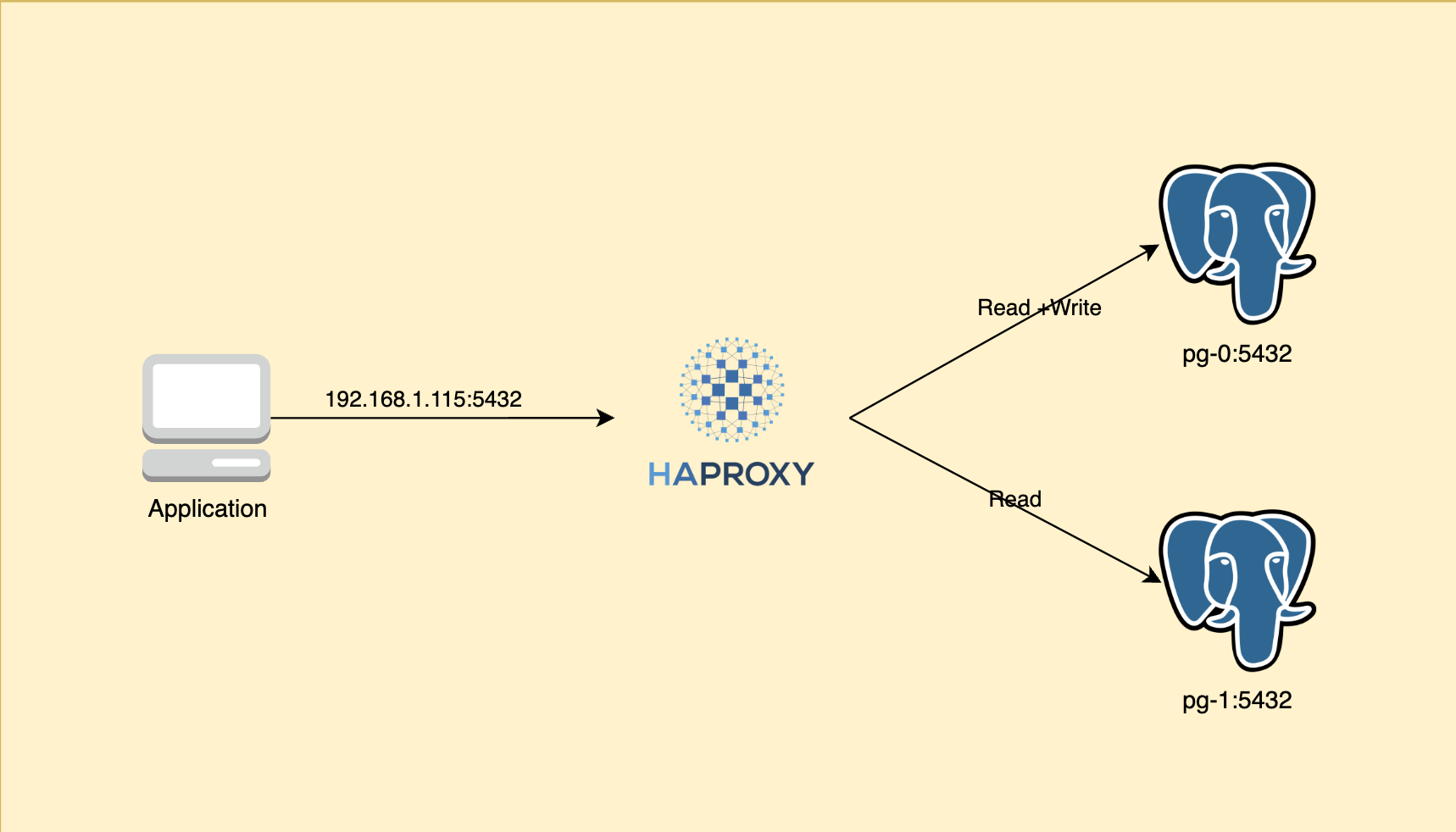
For Demo purpose i will deployed two postgres server using docker compose. haproxy and postgres will share network namespace, so they can communicate by service name. haproxy will expose port 5432 to the host machine.
Deploy PostgreSQL
I will use image from bitnami, they packaged all the need tool for us.
https://hub.docker.com/r/bitnami/postgresql-repmgr
version: '3.9'
networks:
default:
name: pg-repmgr
driver: bridge
volumes:
pg_0_data:
pg_1_data:
x-version-common:
&service-common
image: docker.io/bitnami/postgresql-repmgr:15
restart: always
x-common-env:
&common-env
REPMGR_PASSWORD: repmgr
REPMGR_PARTNER_NODES: pg-0,pg-1:5432
REPMGR_PORT_NUMBER: 5432
REPMGR_PRIMARY_HOST: pg-0
REPMGR_PRIMARY_PORT: 5432
POSTGRESQL_POSTGRES_PASSWORD: postgres
POSTGRESQL_USERNAME: docker
POSTGRESQL_PASSWORD: docker
POSTGRESQL_DATABASE: docker
POSTGRESQL_SHARED_PRELOAD_LIBRARIES: pgaudit, pg_stat_statements
POSTGRESQL_SYNCHRONOUS_COMMIT_MODE: remote_write
POSTGRESQL_NUM_SYNCHRONOUS_REPLICAS: 1
services:
pg-0:
<<: *service-common
volumes:
- pg_0_data:/bitnami/postgresql
environment:
<<: *common-env
REPMGR_NODE_NAME: pg-0
REPMGR_NODE_NETWORK_NAME: pg-0
pg-1:
<<: *service-common
volumes:
- pg_1_data:/bitnami/postgresql
environment:
<<: *common-env
REPMGR_NODE_NAME: pg-1
REPMGR_NODE_NETWORK_NAME: pg-1
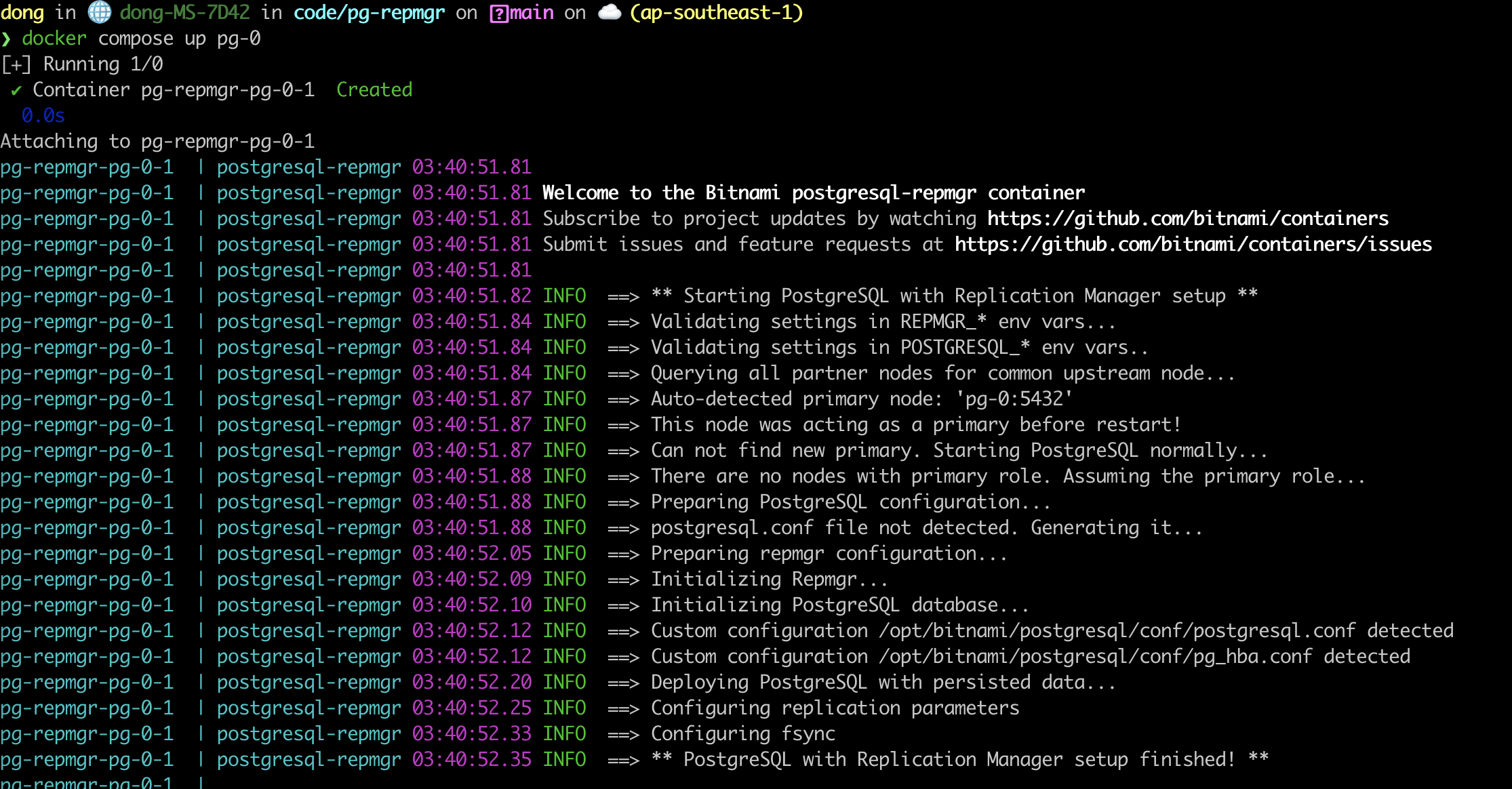
In the docker-compose.yml above, i defined two services, pg-0 and pg-1. pg-0 is the initial primary server. Let deploy it first using docker compose up pg-0
It's up. Then we will deploy pg-1 service docker compose up pg-1
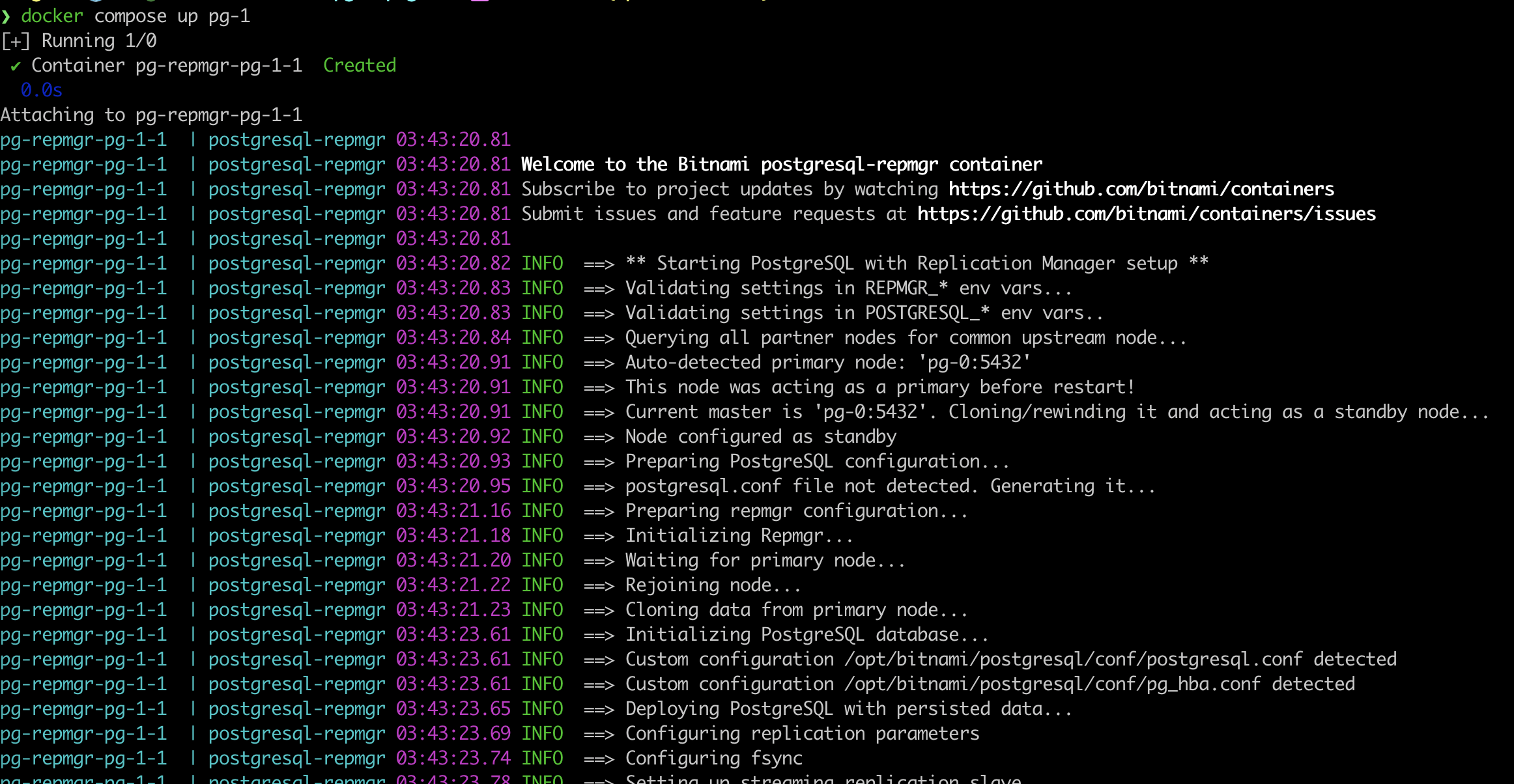
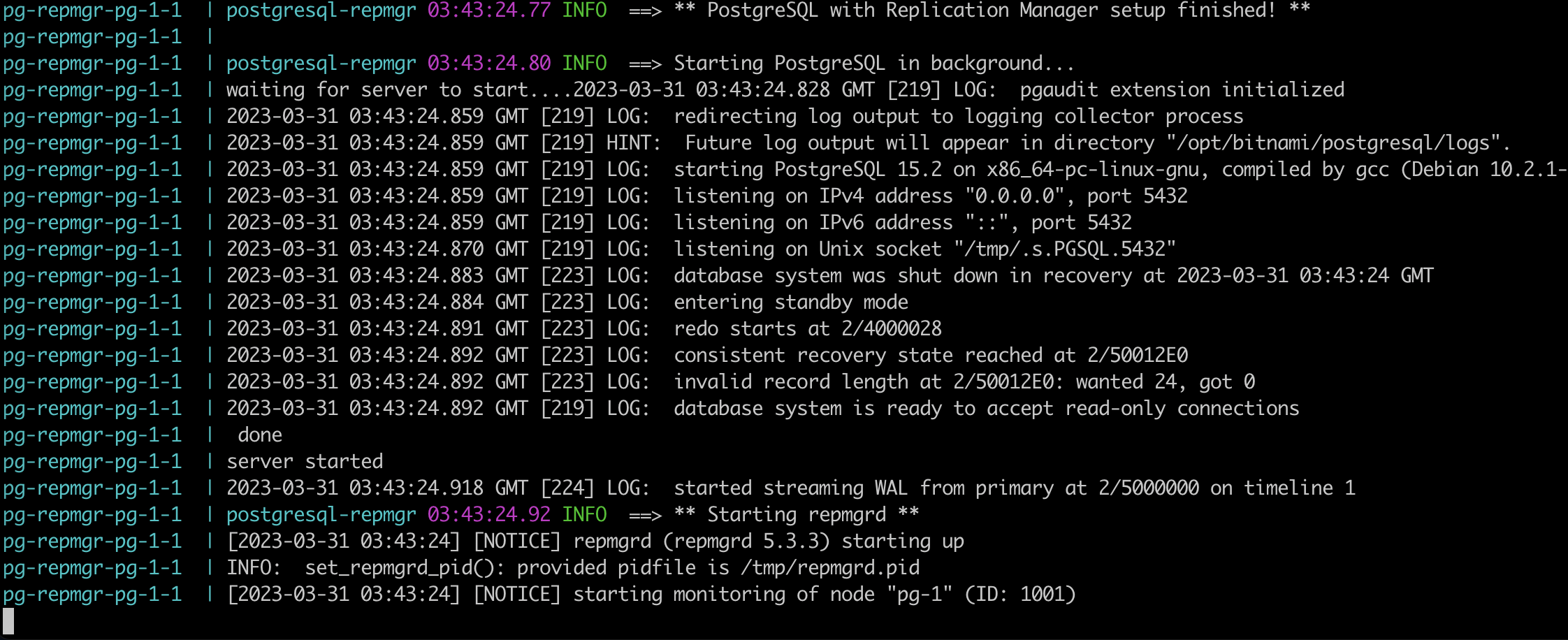
From the log, you will see that pg-1 joined cluster at standby instance.
Go to the pg-0 service and check the log. pg-0 detected new standby server.

Now we already have two server.
Deploy HAPROXY
Add haproxy service to docker-compose.yaml file, also preprare haproxy.cfg for haproxy. Service look like this.
configs:
haproxy:
file: ./haproxy.cfg
services:
haproxy:
image: haproxy
mem_limit: 8192m
ports:
- 3000:3000
- 5432:5432
privileged: true
configs:
- source: haproxy
target: /usr/local/etc/haproxy/haproxy.cfgThe content of haproxy.cfg
global
maxconn 4096
ulimit-n 30000
external-check
insecure-fork-wanted
log stdout format raw daemon notice
resolvers docker
nameserver dns1 127.0.0.11:53
hold valid 10s
defaults
log global
mode tcp
option tcplog
option dontlognull
option tcp-check
option srvtcpka
http-reuse aggressive
timeout client 180m
timeout server 180m
timeout connect 2s1
listen stats
bind *:3000
mode http
stats enable
stats uri /
stats refresh 2s
listen primary
bind *:5432
maxconn 2048
option external-check
external-check command /build-psql/primary-check.sh
default-server resolvers docker init-addr none check inter 2s fall 1 rise 2 slowstart 4000
server pg-0 pg-0:5432
server pg-1 pg-1:5432
listen standy
bind *:5433
maxconn 2048
option external-check
balance roundrobin
external-check command /build-psql/standby-check.sh
default-server resolvers docker init-addr none check inter 2s fall 1 rise 2 slowstart 4000
server pg-0 pg-0:5432
server pg-1 pg-1:5432
In haproxy.cfg config, i defined external health-check command so i can detect which service is primary and also standby. I used function pg_is_in_recovery(), you can check it here.
https://pgpedia.info/p/pg_is_in_recovery.html
The primary-check.sh is look like this.
#!/bin/bash
VIP=$1
VPT=$2
RIP=$3
PG_MONITOR_USER=postgres
PG_MONITOR_PASS=postgres
PG_MONITOR_DB=postgres
if [ "$4" == "" ]; then
RPT=$VPT
else
RPT=$4
fi
STATUS=$(PGPASSWORD="$PG_MONITOR_PASS" /usr/local/pgsql/bin/psql -qtAX -c "select pg_is_in_recovery()" -h "$RIP" -p "$RPT" --dbname="$PG_MONITOR_DB" --username="$PG_MONITOR_USER")
#echo "$@ status=$STATUS"
if [[ "$STATUS" == "f" ]]
then
exit 0
else
exit 1
fiThe standby-check.sh is look like
#!/bin/bash
VIP=$1
VPT=$2
RIP=$3
PG_MONITOR_USER=postgres
PG_MONITOR_PASS=postgres
PG_MONITOR_DB=postgres
if [ "$4" == "" ]; then
RPT=$VPT
else
RPT=$4
fi
STATUS=$(PGPASSWORD="$PG_MONITOR_PASS" /usr/local/pgsql/bin/psql -qtAX -c "select pg_is_in_recovery()" -h "$RIP" -p "$RPT" --dbname="$PG_MONITOR_DB" --username="$PG_MONITOR_USER")
if [[ "$STATUS" == "t" ]]
then
exit 0
else
exit 1
fiDeploy haproxy using docker compose up haproxy
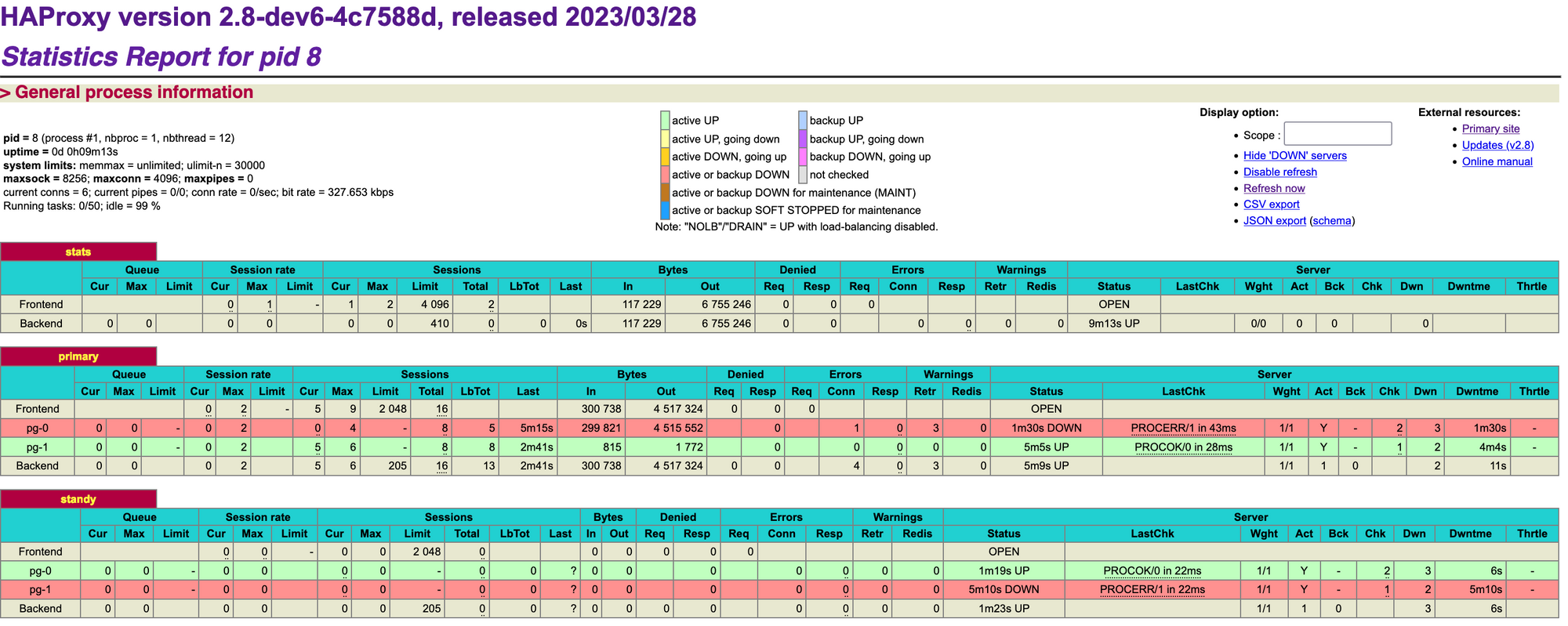
Open http://localhost:3000 to watch stats.
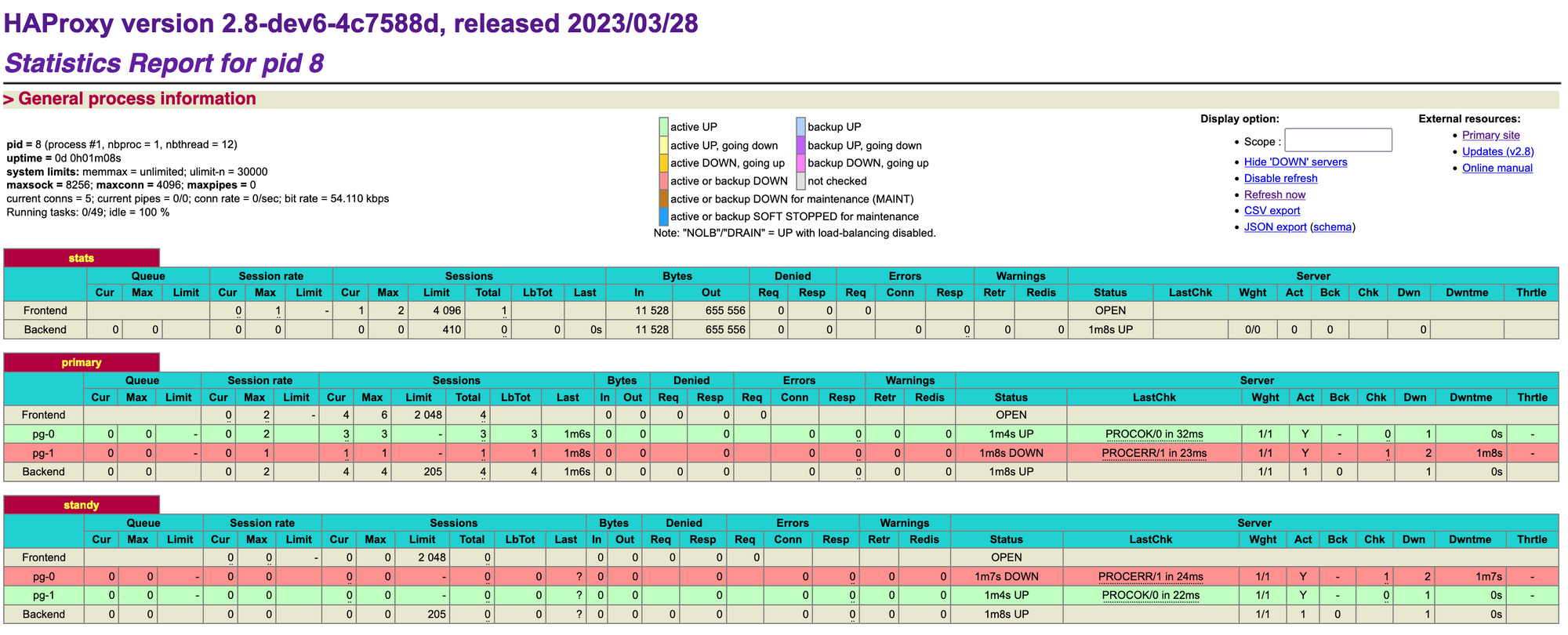
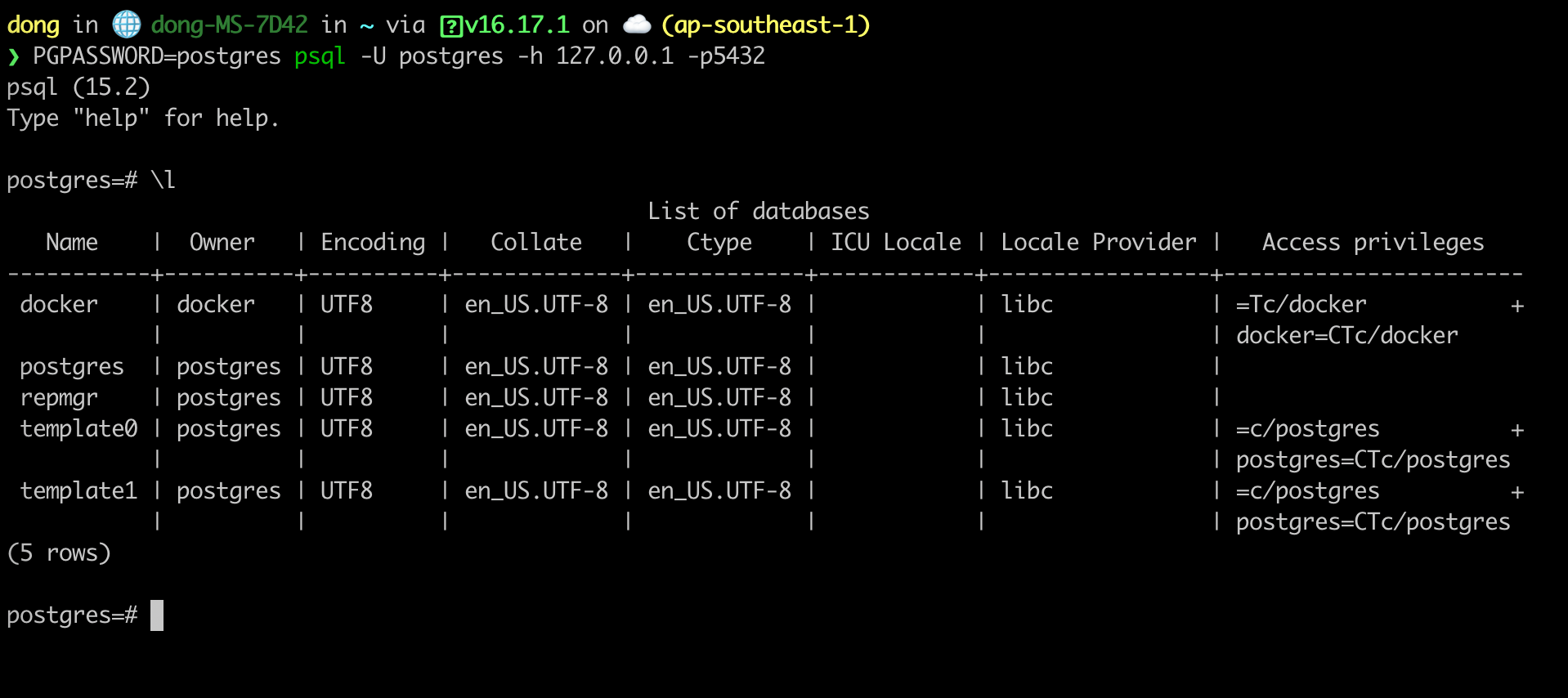
At this moment, haproxy detected the right service for us. pg-0 is primary and pg-1 is standby. Let use psql to send a query to database.
Shutdown pg-0
Time to test if pg-1 will up when our pg-0 dead. Let stop pg-0 service.
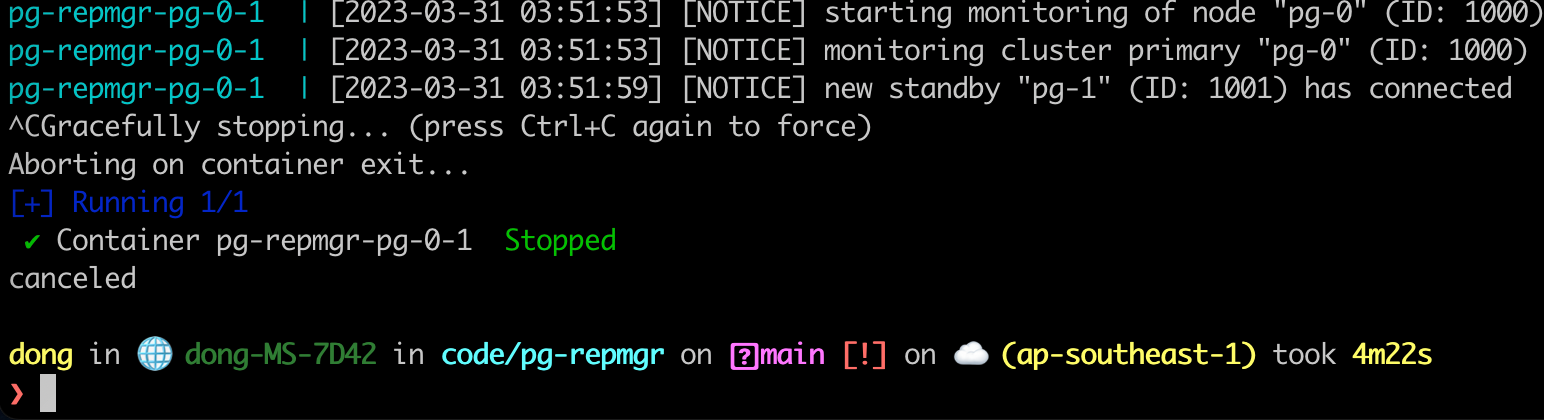
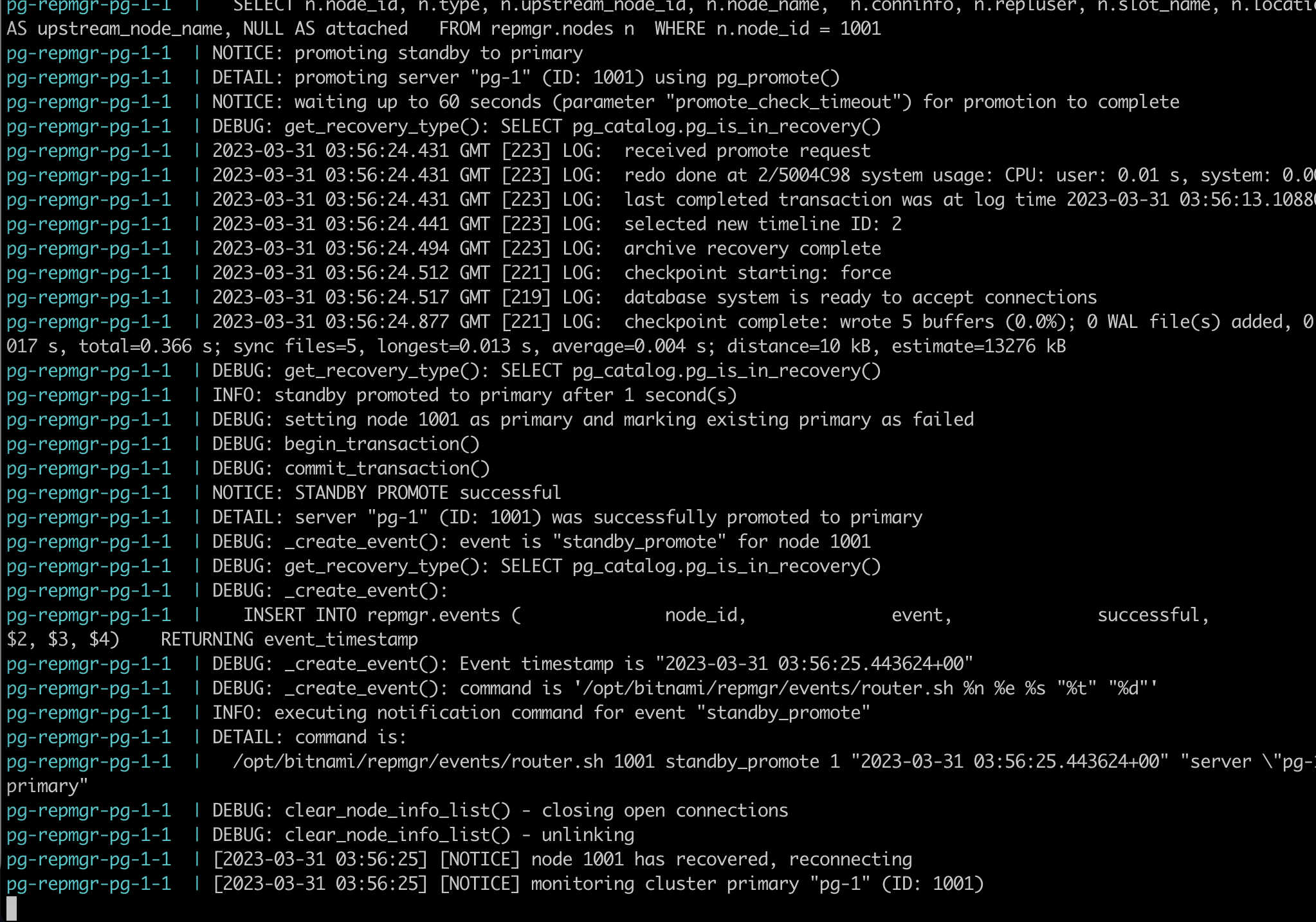
Go the pg-1 service and see the log. You will see it detected the failure of pg-0 and promote itself to be a primary server.
Go to the haproxy dashboard.
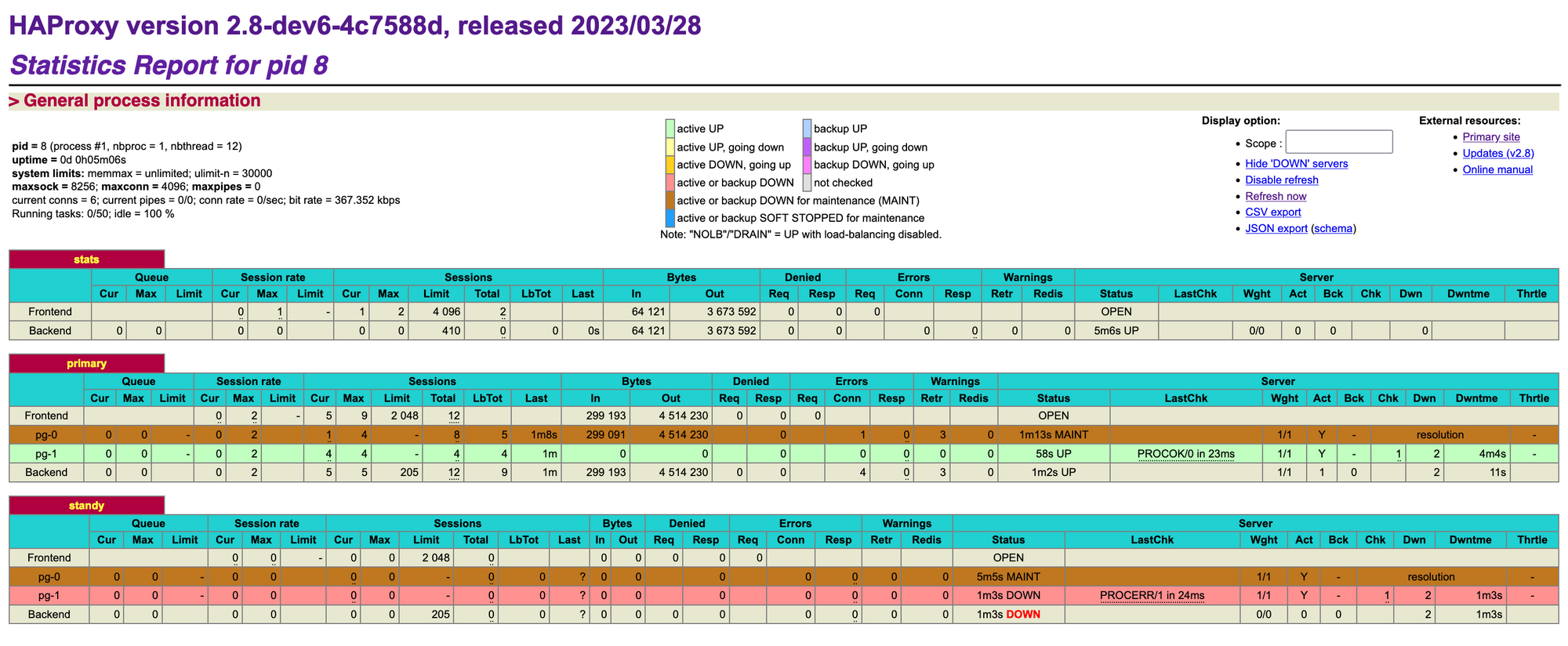
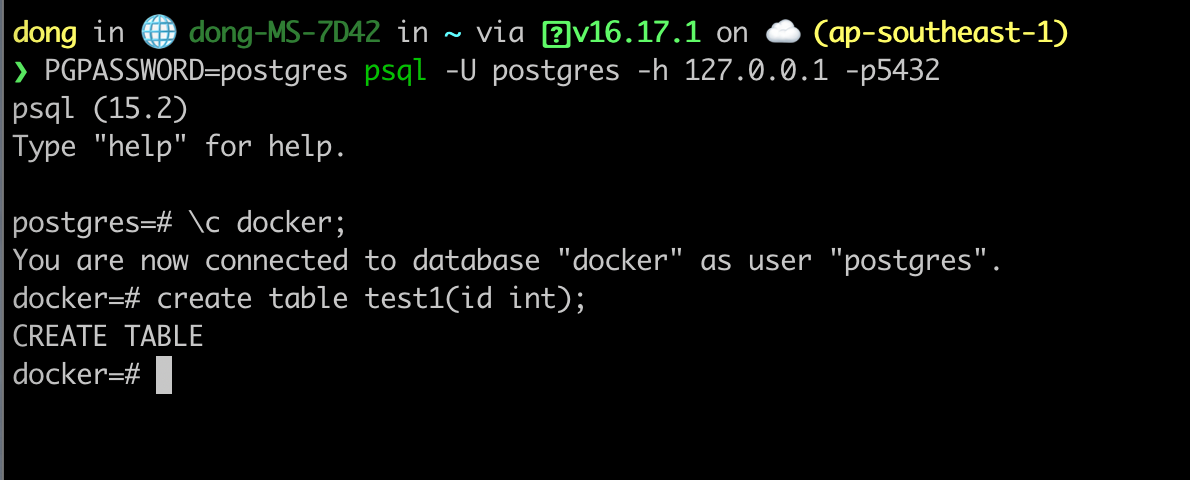
At this moment, haproxy detect that there is no standby server due to pg-0 dead and pg-1 is primary instace. Go to psql try to execute a query. You will be able to do write operation.
Up pg-0
Next time, up pg-0 service, i will expect haproxy will update standby listener status.
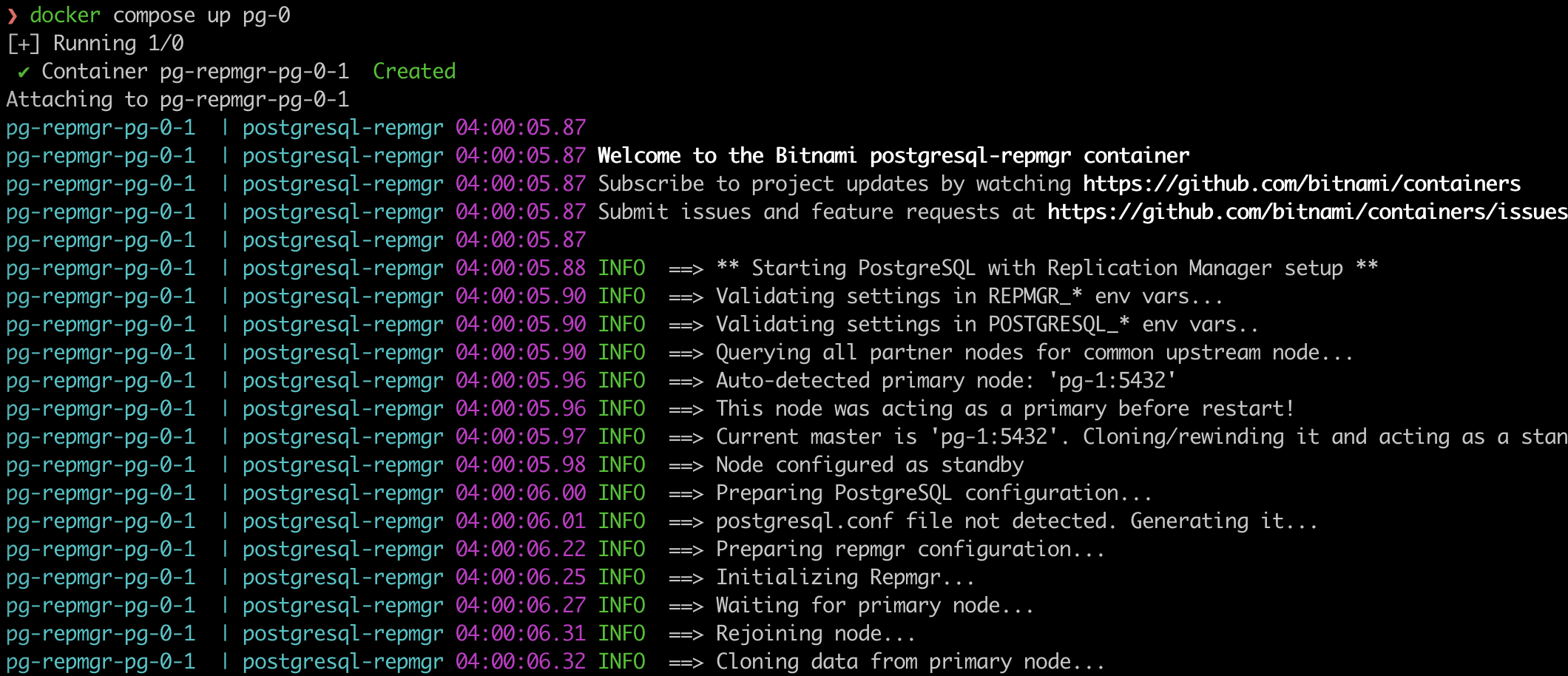
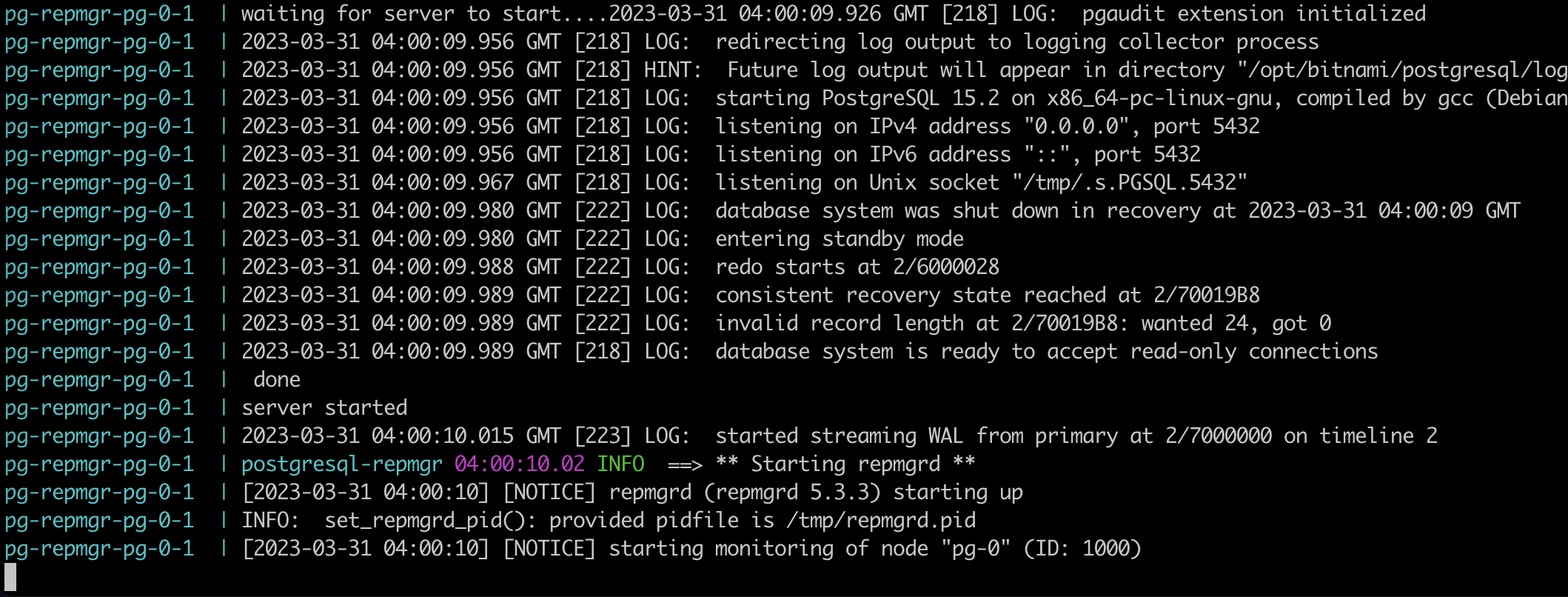
Check the log of pg-1, you will see pg-0 joined at standby server.
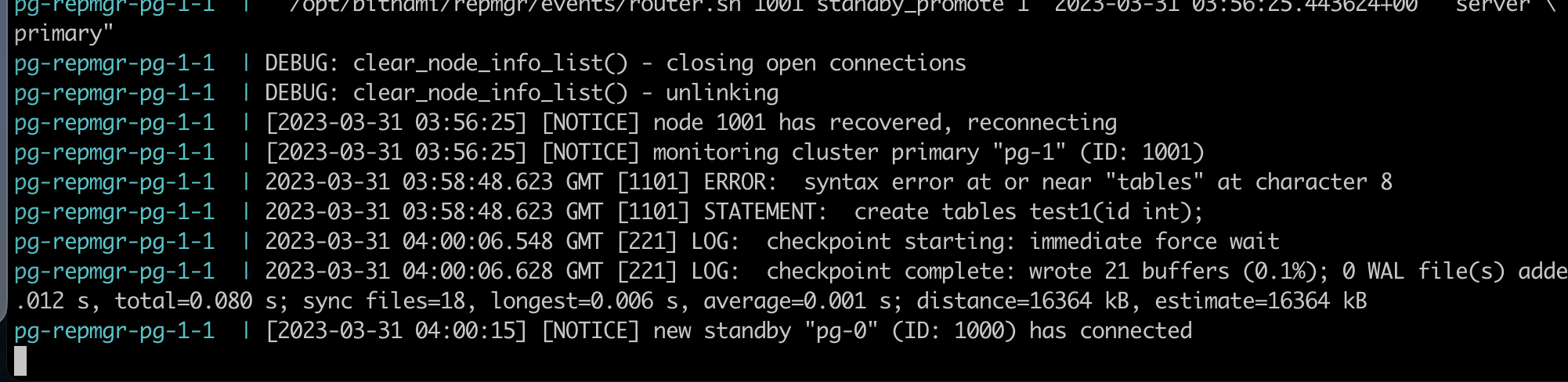
Go to haproxy dashboard, it deteted new standby via check script file.
That is, thank for repmgr, we reduced a lot of effort to manage them. Thank you for reading this post.


