

When we build a large system, we always have at least two main challenges to solve: how to handle large volume of data and how to analyze them. Kafka came as a solution. It's specifically designed for distributing high throughput systems.
This blog is written for a developers who want to use Kafka in service. If you want to dig deeper into Kafka, please read the official document from https://kafka.apache.org. And all of this below is something I thought what you need to know before implement a service using Kafka.
What is Messaging System (MS) ?
A messaging system is responsible for transferring data from one service/application to another. MS have two available types: point to point and publish-subscribe. Most of the MS follow pub-sub pattern.
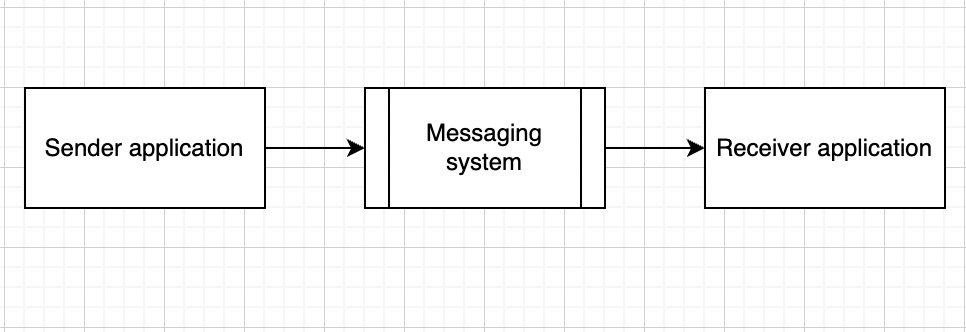
Point-to-point pattern
In a point-to-point system, messages are persisted in a queue. One or more consumers can consume the messages in the queue, but a particular message can be consumed by a maximum of one consumer only. Once a consumer reads a message in the queue, it gets removed.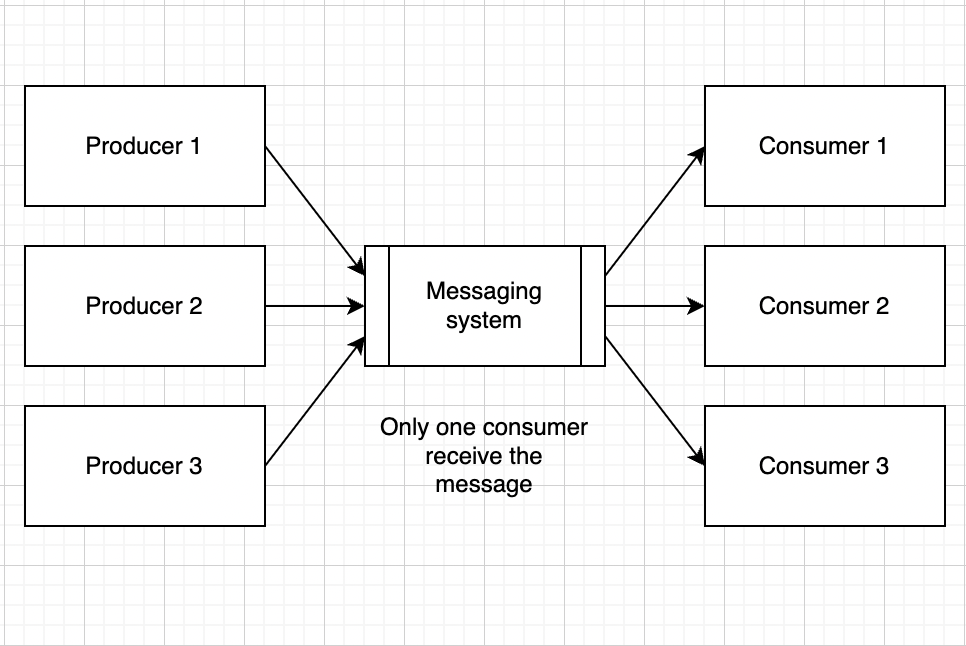
Publish-subscribe pattern
In a publish-subscribe (producer-consumer) pattern, messages are persisted in a topic. A consumer can subscribe to one or many topic and get all the messages in that topic.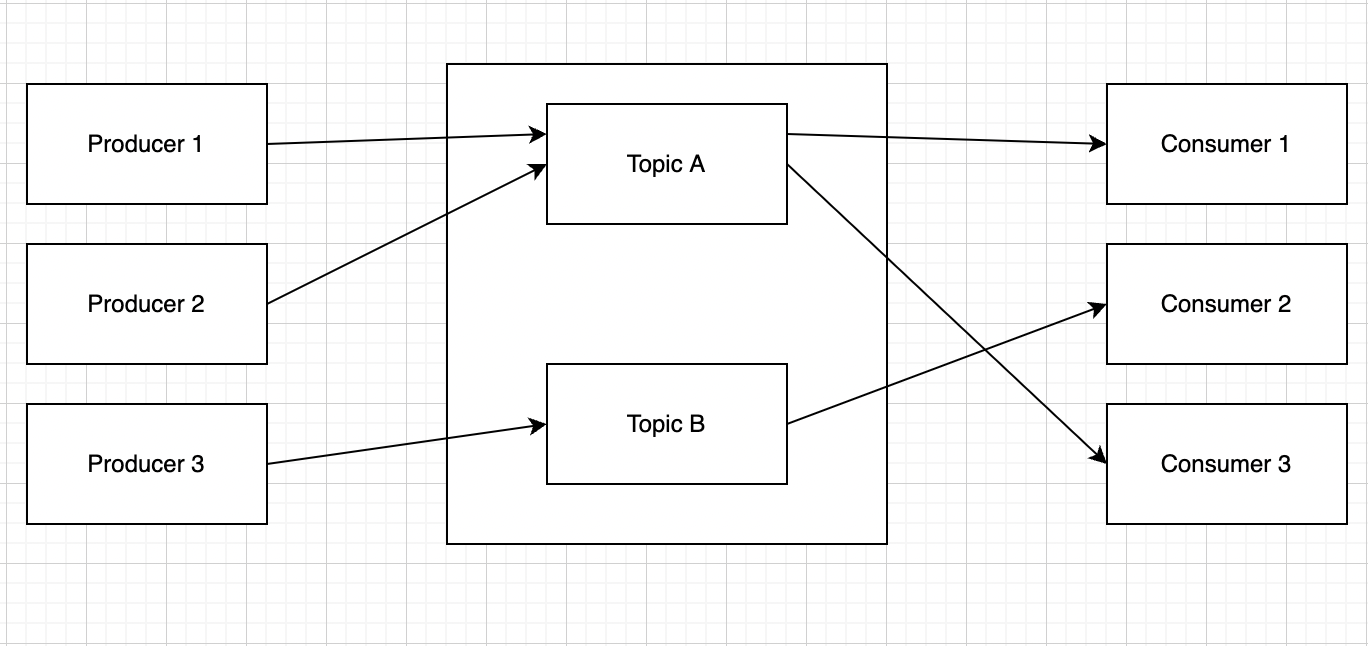
What is Apache Kafka ?
Now we know that Apache Kafka is a messaging system. More specifically, Apache Kafka is a distributed data store optimized for ingesting and processing streaming data in real-time. Streaming data is data that is continuously generated by thousands of data sources, which typically send the data records simultaneously. A streaming platform needs to handle this constant influx of data, and processes the data sequentially and incrementally. Kafka offers a Pub-sub and queue-based messaging system.
Kafka main components
The main kafka components are topics, producers, consumers, consumer groups, clusters, brokers, partitions, replicas, leaders, and followers. But if you are a developer and just work with kafka by code and service then you just need to know about topics, brokers, producers, consumers, consumer groups and partitions.
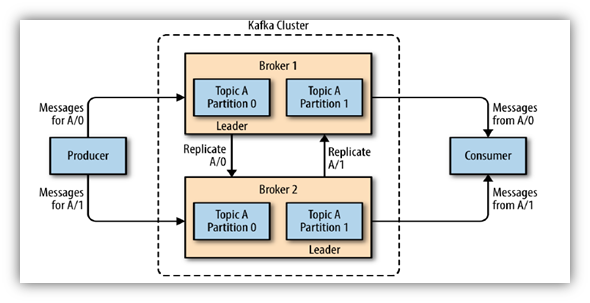
Image from Narayan Kumar - Medium
Producer
Producer or publisher is an application that is the source of the data stream. Kafka producers public API to help handle and sending messages with some data then deliver it to brokers/servers. Every messages send from producer need a destination, which is a topic, broker.
Broker - Topic - Partition
Kafka broker (kafka server) is based on kafka cluster. A kafka cluster consists of one or more brokers.
Each Broker can has one or more Topics. Kafka topics are divided into a number of partitions. Each partition can be placed on a single or multiple separate machines to allow multiple consumers to read from a topic in parallel. Topics are stored message sent from producers with ascending offset.
Consumer - Consumer group
A kafka consumer is the one that consumes or reads data from the kafka cluster via a topic. A consumer also knows from which broker it should read the data. The consumer reads the data within each partitions in an orderly manner. It means the consumer is not supposed to read data from offset 1 before reading from offset 0. Also, consumers can easily read data from multiple brokers at the same time.
A kafka consumer group is a group of multiple consumers. Each consumer in a group reads data directly from the exclusive partitions. And in case the number of consumers are more than the number of partitions, some of the consumers will be in an inactive state. Then, if we lose any active consumer within the group, the inactive one can takeover, become active and read the data.
Summary and pseudo-code
Okayyy, if you are new in kafka and not understand what the matrix text in above, don't worry. Now we will use this pseudo code to understand what it is.
Suppose we have a broker with address: 1.1.1.1:9092.
And we work with topic named: hold_message_topic.
[Global config or Environment]
const BROKER_ADDRESS = "1.1.1.1:9092"
const TOPIC_NAME = "hold_message_topic"
[Producer service]
import Producer from kafka;
// ...
//Create new a producer instance with broker address
Producer producder = new Producer(BROKER_ADDRESS)
public void kafkaProducerHandler(String msg) {
//Wrap message with producer api
Producer.Record record = Producer.Record(msg)
//Send a message with topic name
producer.send(record, TOPIC_NAME)
}
[Consumer service]
import Consumer from kafka;
//...
const GROUP_ID = "group_id_1" //Set group id/consumer group
const POLL_NUMBER = 1 //Message every commit/poll from consumer
const POLL_TIME = 1000 //Delay time every consumer poll message
const READ_OFFSET = "lastest" // consumer read message from now
public void kafkaConsumerHandler() {
//Create new a consumer instance with broker address
Consumer consumer = new Consumer(BROKER_ADDRESS)
//Start consume with some config in above
consumer.consume(TOPIC, {READ_OFFSETT, POLL_TIME})
//Handle message after received
while {
Consumer.Record consumerRecords = consumer.poll(POLL_NUMBER)
for record : consumerRecords {
printOrHandleSomething(record)
}
}
}
Some problems when using Kafka
How to choose number of topics/partitions
If you are producing 100 messages per second and your consumers can process 10 messages per second then you will want at least 10 partitions (produce / consume) with 10 instances of your consumer. If you want this topic to be able to handle future growth, then you will want to increase the partition count even higher so that you can add more instances of consumer to handle the new volume.
Note: Kafka can, at max, assign one partition to one consumer. If there are more number of consumers than the partitions, Kafka would fall short of the partitions to assign.
Rebalance
When a new consumer joins a consumer group or some/any consumer are down, the set of consumers attempt to "rebalance" the load to assign partitions to each consumer. If the set of consumers changes while this assignment is taking place, the rebalance will fail and retry. This setting controls the maximum number of attempts before giving up.
When and why using Kafka

Image from Rinu Gour - Medium
The first thing anyone working with streaming applications should understand is the concept of event. An event is an atomic piece of data. For example, when the user registers with the system, the action creates an event. You can also think about an event like a message with data.
You will consider to using kafka if:
- Your application needs Real-time data processing: Many modern systems require data to be processed as soon as it becomes available. Kafka can be useful here since it is able to transmit data from producers to data handlers and then to data storages
- Your application needs activity tracking or logging, monitoring system: it is possible to publish logs into Kafka topics. The logs can be stored in a Kafka cluster for some time. There, they can be aggregated or processed. It is possible to build pipelines that consist of several producers/consumers where the logs are transformed in a certain way
- Microservice: Kafka can be used in microservices as well. They benefit from Kafka by using it as a centric intermediary that lets them communicate with each other. That way they benefit from the publish-subscribe model
Extra: Why not RabbitMQ ?

Image from Tarun Batra
Of course in design, everything has trade-offs. We're not saying Kafka greater than RabbitMQ, but Kafka have three application-level differences if you consider to choose what to use:
- Kafka supports re-read of consumed messages while RabbitMQ doesn't.
- Kafka supports ordering of messages in partition while RabbitMQ supports it with some constraint such as one exchange routing to the queue, one queue, one consumer to queue.
- Kafka is faster in publishing data to partition than RabbitMQ.