

First let's explore the API Gateway architecture pattern then slowly deep dive into the details of running a production-grade Kong API gateway.
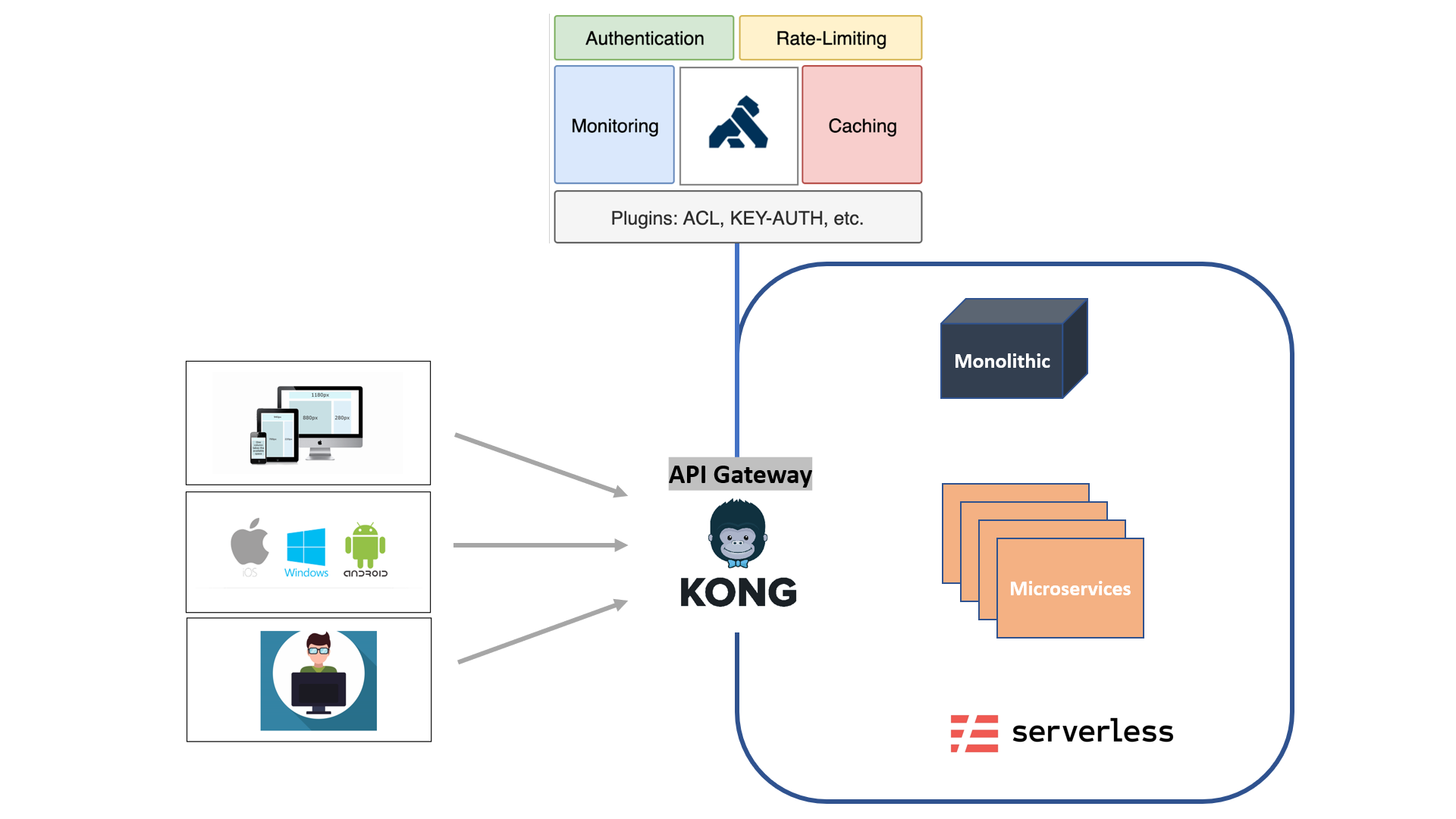
Generally in many organizations, the backend APIs are consumed by multiple front-facing applications like the mobile app, web, and other kiosk applications. In addition, many other internal and external integrators may have a need to consume these APIs. We will end up applying some of the below architecture characteristics to every individual APIs to support the above requirements. That will be a hell lot of work.
- Authentication/Authorization
- Monitoring
- Logging
- Traffic control
- Caching
- Audit and Security
- API Administration
API Gateway Architecture Pattern
API gateway architecture pattern attempts to take away all these cross cutting concerns in managing these APIs and put them all across in a single plane. This will provide us with a lot of architecture advantages like
- A unified way to apply cross-cutting concerns
- Out of the box, plugins to apply cross cutting concerns quickly
- A framework for building custom plugins
- Managing security in a single plane
- Reduced operation complexity
- Easy governance of 3rd part developers and integrators
- Finally saving the cost of development and operations
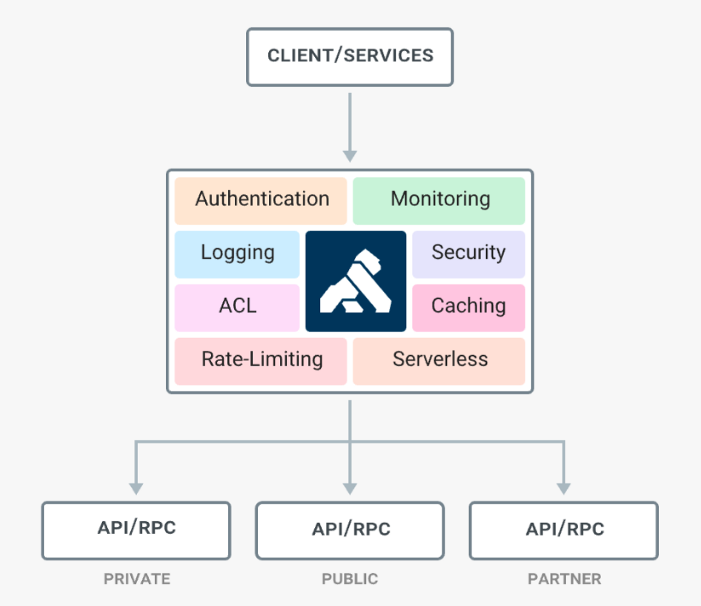
Kong API Gateway
Kong is one of the popular opensource API gateways which can help us to manage APIs deployed anywhere from a simple infrastructure to a complex multi-cloud environment. Kong’s ability to handle different protocols like REST, GRPC, Graphql enables us to manage almost all of our APIs. Kong strikes a perfect balance between the opensource and enterprise offerings.
If you are an organization focused on open-source, Kong comes with an open-source version with very good community support. Also, there is a perfect base framework set for you to extend kong with your own plugin. If you are an enterprise looking for support and some additional features to support large enterprise needs, then Kong Enterprise offering comes to the rescue.
Kong Anatomy
Kong involves two important components:
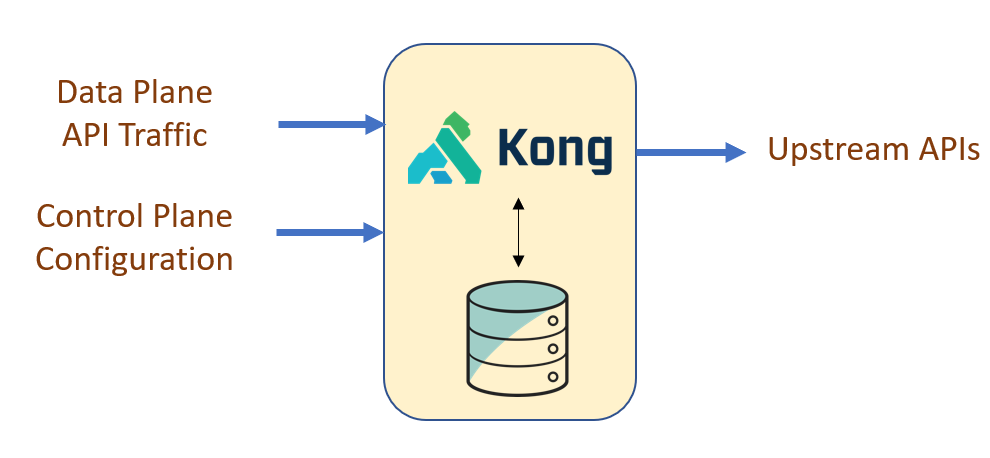
- The kong data plane that handles the actual API proxy itself applying all cross cutting concerns configured for the given API. This is built over Nginx as the base.
- The kong control plane that receives the configuration on how to proxy an API and persist the same. Kong comes with two different persistence model:
- Kong DB Less Mode
- Kong DB Mode
Database Vs Database Less Mode
Kong DB mode persists all the configurations in a DB with a couple of choices(Cassandra / PostgreSQL).
Cassandra has its own advantage of horizontal scaling to match the horizontal scalability of Kong. You are the better judge to decide if you are operating at that scale. It's also important to note that Kong stores all the configuration in memory for better performance. DB is reached mostly to refresh config on change.
To reduce the complexity and create more flexible deployment patterns, Kong 1.1 ships with the ability to enable DB-less mode. In this mode the entire configuration is managed in-memory loaded from a configuration file. This will enable horizontal scaling and works well with Continuous Delivery / Deployment pipelines.
Data Plane, Control Plane Segregation & Security
With the latest version of kong, it is possible to separate control and data planes in a Kong cluster.
On each kong node, there is a port exposed serving the API traffic(data plane), and another port for operators to configure kong(control plane). The ability to enable and disable kong data /control plane will give us the below flexibilities:
1. Making a node control-plane only for operators
2. Making a node data-plane only for API traffic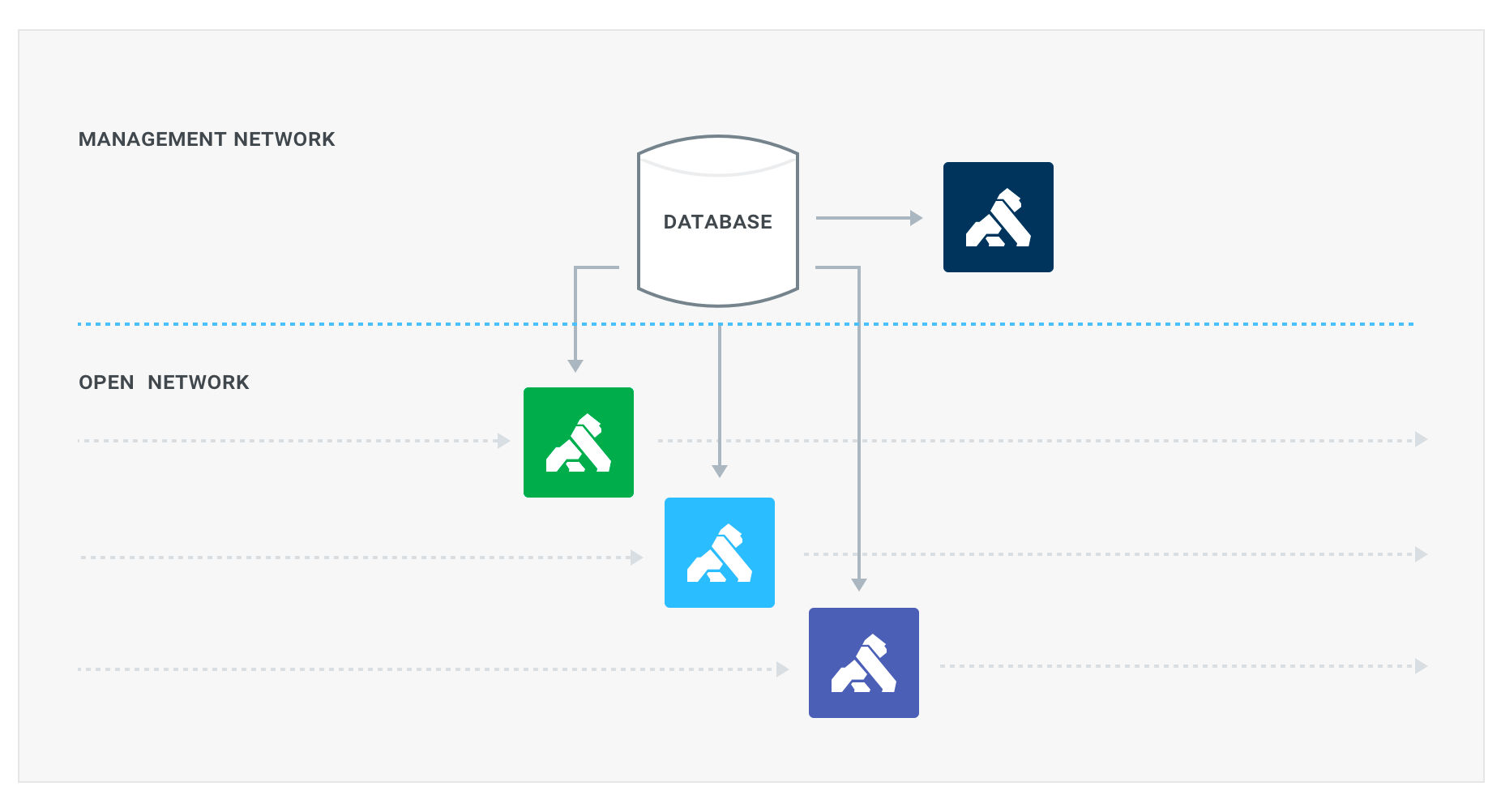
Kong Installation
Kong comes with a wide range of installation options. Some of them are directly supported by kong, while few other options are supported by the community. Look at different installation options here. I personally use docker-based deployment because of its portable. Let's look at a single-node Kong set up with PostgreSQL.
Step 1: Create a docker network to deploy kong and PostgreSQL with connectivity
docker network create kong-net
Step 2: Start the Postgres DB docker into the “kong-net” network
docker run -d — name kong-database — network=kong-net -p 5432:5432 -e “POSTGRES_USER=kong” -e “POSTGRES_DB=kong” -e “POSTGRES_PASSWORD=kong” postgres:9.6
Step 3: Run migration script on the Postgres DB and get it ready for Kong
docker run — rm — network=kong-net -e “KONG_DATABASE=postgres” -e “KONG_PG_HOST=kong-database” -e “KONG_PG_PASSWORD=kong” kong:latest kong migrations bootstrap
Step 4: Start the actual kong docker
docker run -d — name kong — network=kong-net -e “KONG_DATABASE=postgres” -e “KONG_PG_HOST=kong-database” -e “KONG_PG_PASSWORD=kong” -e “KONG_PROXY_ACCESS_LOG=/dev/stdout” -e “KONG_ADMIN_ACCESS_LOG=/dev/stdout” -e “KONG_PROXY_ERROR_LOG=/dev/stderr” -e “KONG_ADMIN_ERROR_LOG=/dev/stderr” -e “KONG_ADMIN_LISTEN=0.0.0.0:8001, 0.0.0.0:8444 ssl” -p 8000:8000 -p 8443:8443 -p 127.0.0.1:8001:8001 -p 127.0.0.1:8444:8444
Check if kong is up and running with the following command:
curl -i http://localhost:8001/
Kong For Kubernetes
If all of your APIs exist within a Kubernetes cluster, the best way to deploy kong is by using the Kong Ingress controller. This installs a couple of containers in a pod, one acting as a control pane and other the data pane. The advantage of this model is that it's Kubernetes-native and automatically discovery APIs through the API server.
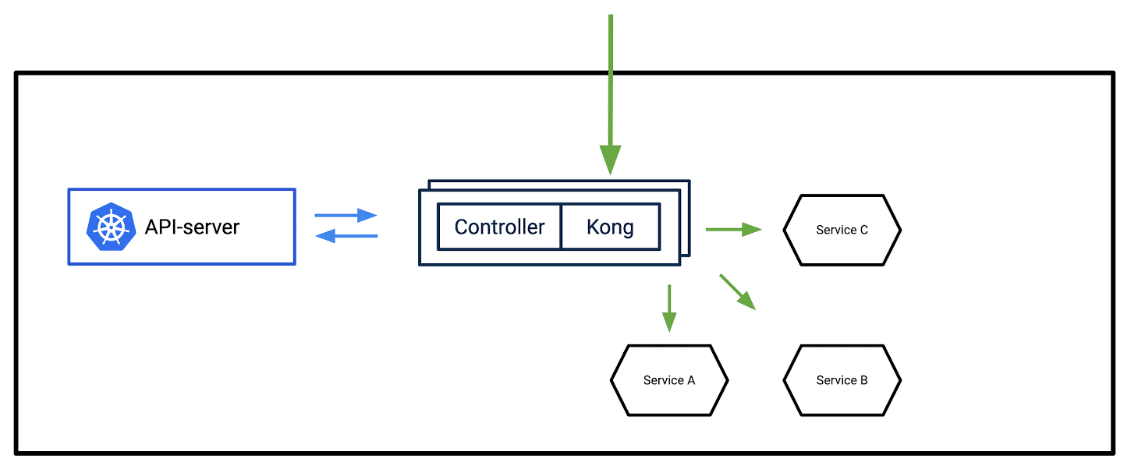
Installing kong into Kubernetes is pretty simple. Run the below kubectl:
kubectl apply -f https://bit.ly/kong-ingress-dbless
This will setup kong with ETCD persistence, few CRD, and a POD with both controller and kong proxy.
Kong Configuration
There is a few terminologies needed to configure kong:
Service — The kong object that binds the upstream API with kong
curl -i -X POST — url http://localhost:8001/services/ — data ‘name=example-service’ — data ‘url=http://test.com'
In the above example, we create a service named “example-service” pointing to an upstream API “http://test.com”. “http://localhost:8001/services/” is the kong admin endpoint to create a service object
Route — The kong object that binds a service with route path for the API consumers
curl -i -X POST — url http://localhost:8001/services/example-service/routes — data ‘hosts[]=example.com&paths[]=/test’
In the above example, we create a route for the “example-service” service pointing to the path “/mockbin”. “http://localhost:8001/services/{service-name}/routes” is the kong admin endpoint to create a route object under the specific service.
Now hit http://localhost:8000/test/, to see if the proxy is working. There are many nuances to configure APIs. See detailed document at doc.
If you are using Kong for Kubernetes, the technologies remain the same. But the configuration will be a Kubernetes custom resource YAML.
Plugins
Plugins are the extensions that we can use to extend kong. There are many open-source plugin implementations of cross-cutting concerns like Basic Authentication, JWT, LDAP Authentication, IP Restriction, Rate Limiting, Prometheus, Zipkin, etc. Enterprise version of kong comes with a lot more plugin. Getting into plugins is a big topic by itself. Read more about individual plugins here.
That's it! Thank you for reading!!!